Thread thread = new Thread(() -> { System.out.println("搵食艰难"); }); thread.start();
}
启动线程:start方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
publicsynchronizedvoidstart(){ ... try { start0(); started = true; } finally { try { if (!started) { group.threadStartFailed(this); } } catch (Throwable ignore) { /* do nothing. If start0 threw a Throwable then it will be passed up the call stack */ } } }
enum ThreadState { ALLOCATED, // Memory has been allocated but not initialized INITIALIZED, // The thread has been initialized but yet started RUNNABLE, // Has been started and is runnable, but not necessarily running MONITOR_WAIT, // Waiting on a contended monitor lock CONDVAR_WAIT, // Waiting on a condition variable OBJECT_WAIT, // Waiting on an Object.wait() call BREAKPOINTED, // Suspended at breakpoint SLEEPING, // Thread.sleep() ZOMBIE // All done, but not reclaimed yet };
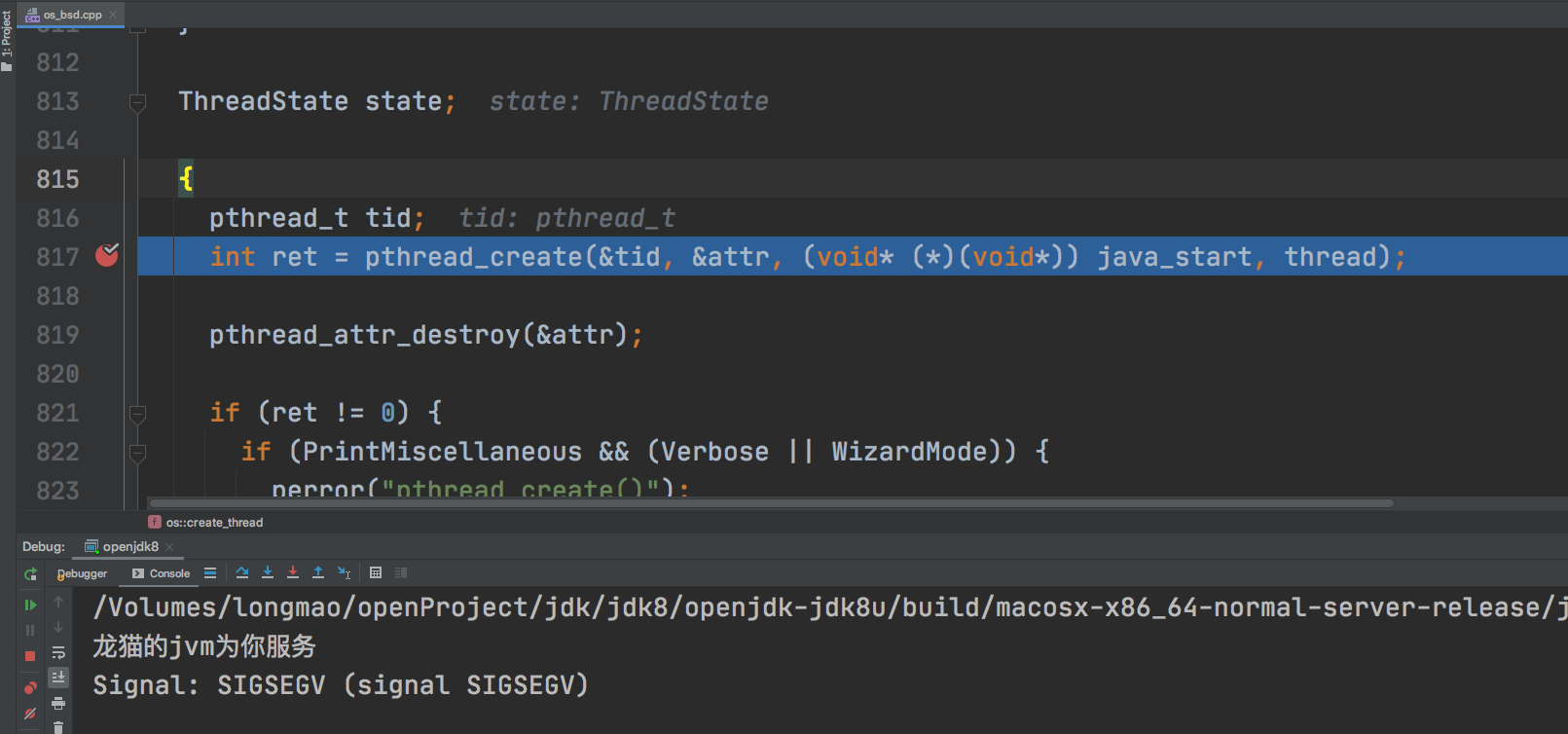
有没有觉得有点眼熟~ 最关键的步骤是通过操作系统函数创建系统线程:
1
int ret = pthread_create(&tid, &attr, (void* (*)(void*)) java_start, thread);