
索引和Btree简介
当我们考虑数据库的性能时,首先想到的是索引。 在这里,我们将研究数据库索引如何在数据库上工作。
Btree 是一种数据结构,将数据按排序顺序存储在其节点中。 我们可以将样本 Btree 表示如下:
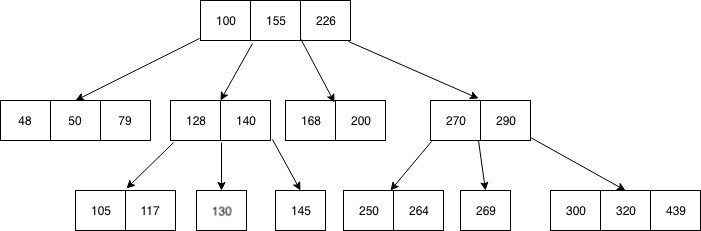
Btree 存储数据,使得每个节点都包含按升序排列的键。 这些键中的每一个都具有对另外两个子节点的两个引用。 左侧子节点键小于当前键,右侧子节点键大于当前键。 如果单个节点有n个键,那么它最多可以有n+1个子节点。
为什么在数据库中使用索引
认为您需要将数字列表存储在文件中并在该列表中搜索给定的数字。 最简单的解决方案是将数据存储在数组中,并在新值出现时附加值。 但是,如果您需要检查给定值是否存在于数组中,则需要一一搜索所有数组元素并检查给定值是否存在。 如果你足够幸运,你可以在第一个元素中找到给定的值。 在最坏的情况下,该值可能是数组中的最后一个元素。 我们可以用渐近符号将这种最坏情况表示为 O(n)。 这意味着,如果您的数组大小最多为n,则您需要执行n+1次搜索才能在数组中找到给定值。
你怎么能减少这个搜索时间? 最简单的解决方案是对数组进行排序并使用二分查找来查找值。 每当您将值插入数组时,它都应该保持顺序。 从数组中间选择一个值开始搜索。 然后将所选值与搜索值进行比较。 如果选择的值大于搜索值,则忽略数组的左侧并搜索右侧的值,反之亦然。
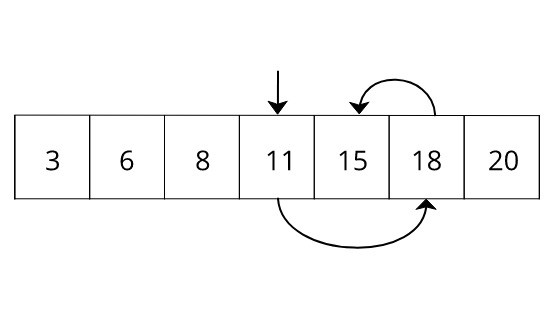
在这里,我们尝试从已经排序好的数组 3,6,8,11,15,18 和 18 中搜索键 15。 如果您进行正常搜索,则从第五个位置的元素开始搜索将花费五个单位的时间。 但是,在二分搜索中,它只需要三个搜索。
如果我们将此二分查找应用于数组中的所有元素,那么它将如下所示。
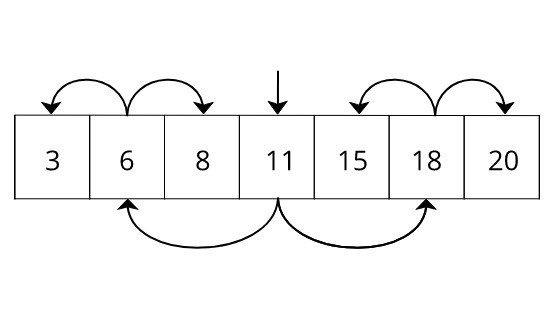
看着眼熟? 它是一棵二叉树。 这是 Btree 的最简单形式。 对于二叉树,我们可以使用指针而不是将数据保存在排序数组中。 从数学上我们可以证明二叉树的最坏情况搜索时间是 O(log(n))。 二叉树的概念可以扩展为更广义的形式,称为 Btree。 Btree 不是为单个节点使用单个条目,而是为单个节点使用条目数组,并为每个条目引用子节点。 下面对每种预先描述的方法进行一些时间复杂度比较。
1 | ┌────────────────┬───────────┬────────────┬───────────┐ |
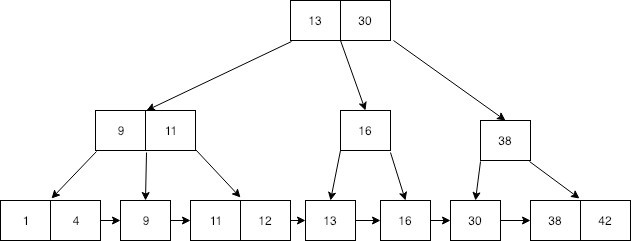
B+tree 是另一种用于存储数据的数据结构,看起来与 Btree 几乎相同。 B+tree 的唯一区别是它在叶子节点上存储数据。 这意味着所有非叶节点值再次在叶节点中重复。 下面是一个示例 B+树。
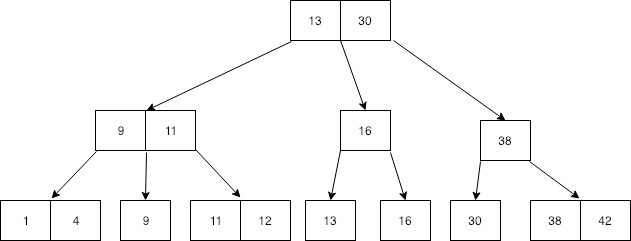
这里 13、30、9、11、16、38 个非叶值再次在叶节点中重复。 你能在叶子节点看到这棵树的特长吗?
是的,叶节点包括所有值,所有记录都按排序顺序排列。 B+tree 的特点是,您可以进行与 Btree 相同的搜索,此外,如果我们如下放置一个指向每个叶节点的指针,您可以遍历叶节点中的所有值。
数据库中如何使用索引?
当 Btree 涉及到数据库索引时,这个数据结构变得有点复杂,不仅有一个键,而且还有一个与键关联的值。 该值是对实际数据记录的引用。 此键和值一起称为有效负载。
假设以下三列表需要存储在数据库中。
| Name | Marks | Age |
|---|---|---|
| Jone | 5 | 28 |
| Alex | 32 | 45 |
| Tom | 37 | 23 |
| Ron | 87 | 13 |
| Mark | 20 | 48 |
| Bob | 89 | 32 |
首先,数据库为每个给定记录创建一个唯一的随机索引(或主键),并将相关行转换为字节流。 然后它将每个键和记录字节流存储在 B+树上。 这里,随机索引用作索引的键。 密钥和记录字节流统称为有效载荷。 得到的 B+tree 可以表示如下。
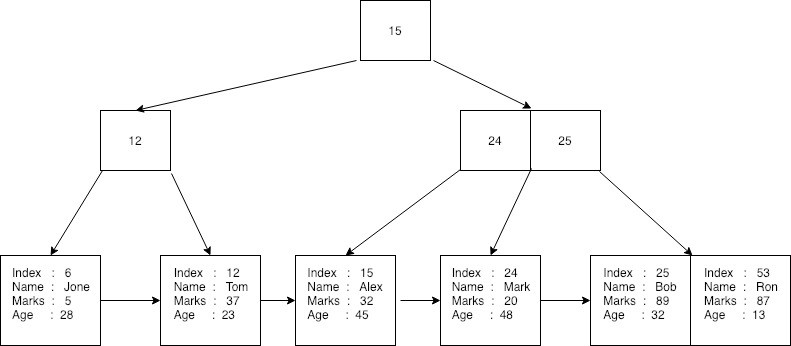
在这里可以看到,所有记录都存储在 B+tree 的叶子节点中,索引作为创建 B+tree 的 key。 没有记录存储在非叶节点上。 每个叶节点都引用了树中的下一条记录。 数据库可以通过使用索引或顺序搜索来执行二分查找,方法是仅通过叶节点来搜索每个元素。
如果没有使用索引,那么数据库读取这些记录中的每一个以找到给定的记录。 启用索引后,数据库会为表中的每一列创建三个 Btree,如下所示。 这里的键是用于索引的 Btree 键。 索引是对实际数据记录的引用。
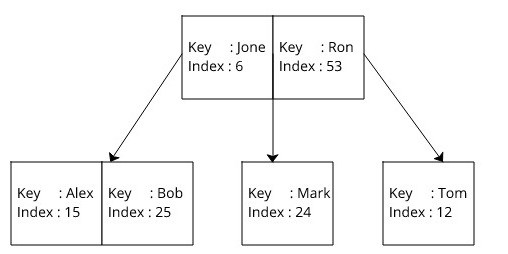
使用索引时首先,数据库在对应的 Btree 中搜索给定的键,并在 O(log(n)) 时间内获得索引。 然后它在 O(log(n)) 时间内使用已经找到的索引在 B+tree 中执行另一次搜索并获取记录。
数据库页实现
Btree 和 B+tree 中的每个节点都存储在 Pages 中。 页面大小固定。 页面具有从一开始的唯一编号。 通过使用页码,一个页面可以是对另一个页面的引用。 在页面的开头,页面元详细信息,例如最右边的子页号、第一个空闲单元格偏移量和存储的第一个单元格偏移量。 数据库中可以有两种类型的页面。
- 用于索引的页面:这些页面仅存储索引和对另一个页面的引用。
- 存储记录的页面:这些页面存储实际数据,页面应该是叶子页面。
总结
数据库应该有一种有效的方式来存储、读取和修改数据。 Btree 提供了一种高效的方式来插入和读取数据。 在实际的Database实现中,Database同时使用Btree和B+tree来存储数据。 Btree 用于索引,B+tree 用于存储实际记录。 B+tree 除了二叉搜索之外还提供顺序搜索功能,这使数据库可以更好地控制在数据库中搜索非索引值。
翻译自:https://github.com/madushadhanushka/simple-sqlite/tree/master/blog