// 1. building the component stack: LifecycleComponent server; try { server = buildBookieServer(new BookieConfiguration(conf)); } catch (Exception e) { log.error("Failed to build bookie server", e); return ExitCode.SERVER_EXCEPTION; }
// 2. start the server try { ComponentStarter.startComponent(server).get(); } catch (InterruptedException ie) { Thread.currentThread().interrupt(); // the server is interrupted log.info("Bookie server is interrupted. Exiting ..."); } catch (ExecutionException ee) { log.error("Error in bookie shutdown", ee.getCause()); return ExitCode.SERVER_EXCEPTION; } return ExitCode.OK; }
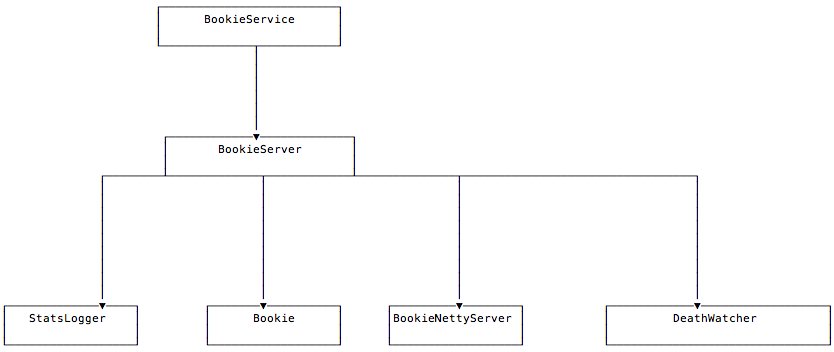
注释很清晰,可以看到启动bookie服务主要做这三步:
解析system property
构建bookie服务所需的组件
启动各个组件
解析system property
1 2
BasicParser parser = new BasicParser(); CommandLine cmdLine = parser.parse(BK_OPTS, args);
system property是java应用程序自身指定的变量,通常我们可以在启动应用的时候指定的,格式是:-DsystemPropertyKey=systemPropertyValue(楼主在本地启动bookie服务在idea设置的Program rguments:–conf /Volumes/longmao/bookkeeper-confg/b1.conf),解析system property使用了apache开源工具commons-cli(自己写应用或框架可以借鉴下其写法,用来加载应用自定义的配置)。
if (conf.getServerConf().isLocalScrubEnabled()) { serverBuilder.addComponent( new ScrubberService( rootStatsLogger.scope(ScrubberStats.SCOPE), conf, bookieService.getServer().getBookie().getLedgerStorage())); }
// 3. build auto recovery if (conf.getServerConf().isAutoRecoveryDaemonEnabled()) { AutoRecoveryService autoRecoveryService = new AutoRecoveryService(conf, rootStatsLogger.scope(REPLICATION_SCOPE));